
A Tour of Iceberg Catalogs with PyIceberg

Let’s talk about Iceberg catalogs. The concept is well-explained by the Iceberg documentation. In this post, we’ll focus on connecting to specific Iceberg catalog implementations using PyIceberg.
What is PyIceberg?
PyIceberg is a “Python implementation for accessing Iceberg tables, without the need of a JVM.” PyIceberg is a Python library that adheres to the Iceberg specification and works out-of-the-box with the Python ecosystem.

{kind=link}
Learn more at https://py.iceberg.apache.org/
Components of an Iceberg Catalog
The Iceberg Catalog consists of
A data store to map table name to metadata JSON file
A filesystem to store metadata files
Metadata JSON file
Manifest List
Manifest File
At its core, the Iceberg Catalog performs translation from a table name to a reference of the table’s current metadata JSON file. The metadata JSON file defines the rest of the table state, such as its schema, partition, and underlying data.
The catalog also performs atomic updates, to swap the existing metadata JSON reference with the updated one. This ensures Iceberg table updates are ACID compliant.
(No Iceberg post is complete without referencing this diagram)
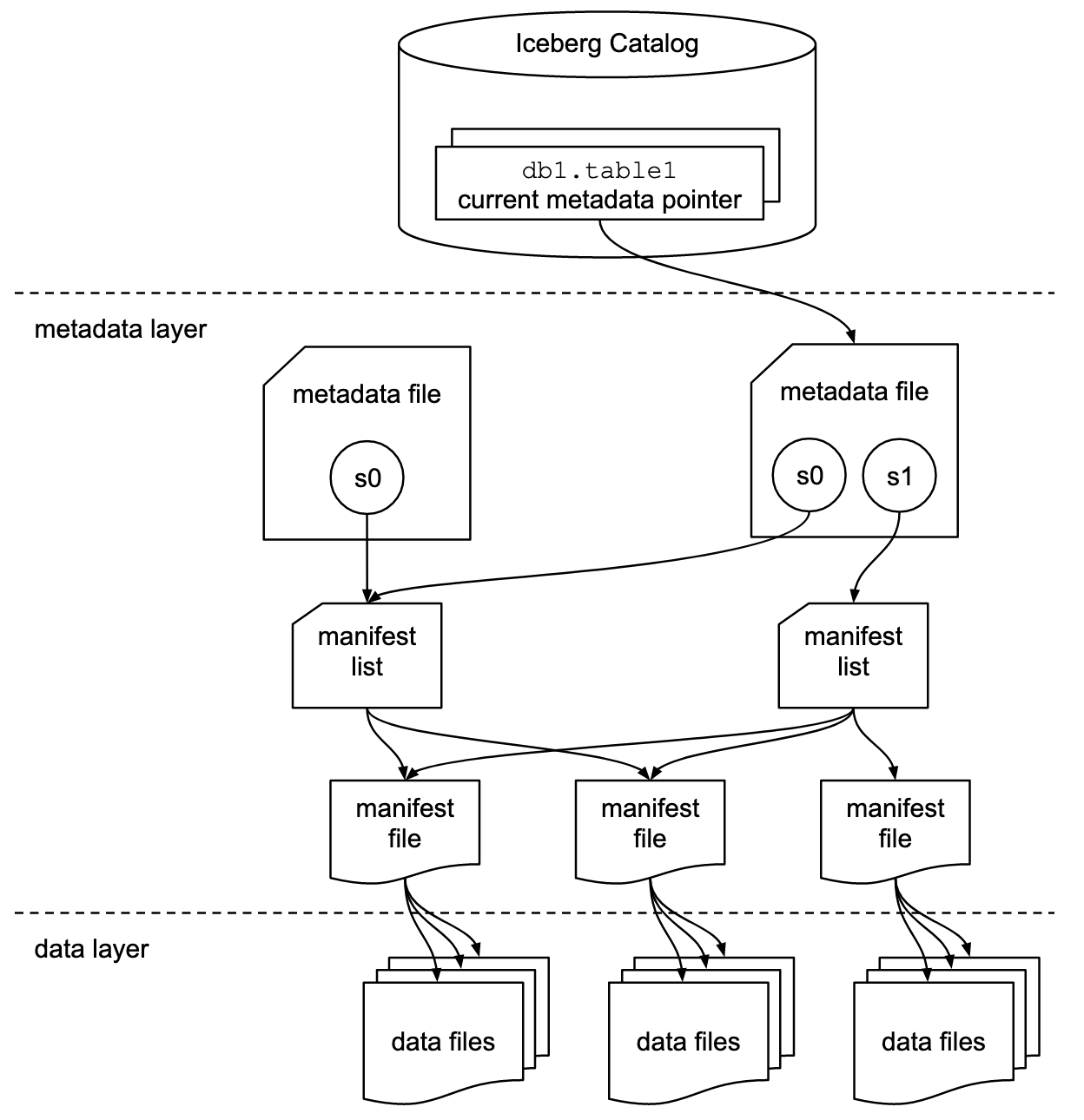
Source: https://iceberg.apache.org/spec/#overview
Iceberg Catalog Implementations
Here’s a list of currently supported Iceberg Catalog implementations in PyIceberg:
SQL Catalog
Hive Catalog
Glue Catalog
DynamoDB Catalog
And a few “specialized” catalogs
InMemory Catalog
Custom Catalog
REST Catalog
PyIceberg can be thought of as the “client” of these catalogs. PyIceberg connects to a catalog and performs read/write operations against the specific implementation.
Catalogs must be configured. There are several ways to pass the configuration parameters.
Using the `~/.pyiceberg.yaml` configuration file
Through environment variables
By passing in credentials through the CLI or the Python API
These methods are explained in depth in the configuration documentation.
In PyIceberg, connecting to the catalog can be abstracted away by using the `load_catalog` function. The function will automatically search for configuration parameters through the ways described above.
For example:
from pyiceberg.catalog import load_catalog
catalog = load_catalog("default")
tbl = catalog.load_table(“foo.bar”)In this post, we’ll be more explicit and express the catalog configurations as a Python dictionary using the Python API.
SQL Catalog
SQL Catalog utilizes a database to store the metadata pointer (table name -> metadata JSON file).
PyIceberg supports PostgreSQL and SQLite through psycopg2. The catalog uses the `uri` property to configure the database connection, which follows the SQLAlchemy URL format.
Read more from the SQL Catalog documentation.
For example:
from pyiceberg.catalog.sql import SqlCatalog
warehouse_path = "/tmp/warehouse"
catalog = SqlCatalog(
"default",
**{
"uri": f"sqlite:///{warehouse_path}/pyiceberg_catalog.db",
"warehouse": f"file://{warehouse_path}",
},
)This creates a SQL Catalog using SQLite as the underlying database. The SQLite database is stored on disk as a file named `/tmp/warehouse/pyiceberg_catalog.db`. Note, that the folder `/tmp/warehouse/` must be created first.
The `warehouse` parameter specifies where the metadata files should be stored. The catalog will write metadata files on disk in the `/tmp/warehouse/` directory.
This example works in the local environment. In cloud environments, the database URI can point to a cloud database connection string such as for AWS RDS or Aurora.
Hive Catalog
The Hive Catalog requires an underlying Hive Metastore instance to store information.
Connection to the Hive Metastore is done via the thrift protocol. The Hive Catalog uses the `uri` property to configure the connection to the Hive Metastore.
Read more from the Hive Catalog documentation.
Spin up a Hive Metastore instance
The PyIceberg repo spins up a Hive Metastore instance using docker for integration tests. The Hive Metastore container is defined in `dev/docker-compose-integration.yml`.
Run the following command in the PyIceberg repo to start the `hive` service,
docker compose -f dev/docker-compose-integration.yml up -d hiveThis will spin up a docker container for the Hive Metastore and expose port 9083.
Connect to Hive Metastore instance
For example:
from pyiceberg.catalog.hive import HiveCatalog
warehouse_path = "/tmp/warehouse"
catalog = HiveCatalog(
"default",
**{
"uri": "http://localhost:9083",
"warehouse": f"file://{warehouse_path}",
}
)Glue Catalog
Glue Catalog refers to the AWS Glue Data Catalog, an AWS service for storing metadata for datasets.
The Glue Catalog requires the necessary AWS credentials to run. Setting up the AWS credential is outside the scope of this post.
Once the AWS credentials are configured, no additional setup is necessary.
Read more from the Glue Catalog documentation.
For example:
from pyiceberg.catalog.glue import GlueCatalog
catalog = GlueCatalog(
"default",
**{
"glue.region": "us-west-2",
"client.access-key-id": "",
"client.secret-access-key": "",
"client.session-token": ""
"warehouse": "s3://iceberg-rest-catalog",
"s3.region": "us-east-1",
}
)A few things to note about the Glue Catalog.
The AWS Glue Data Catalog is region-specific. A catalog in the `us-east-1` AWS region is completely isolated from another catalog in the `us-west-2` AWS region.
Separate AWS credentials can be set for the Glue catalog and the S3 FileIO. The Glue AWS credentials are prefixed with `glue.` and the S3 with `s3.`. One can use the same AWS credential for both services by using the `client.` prefix when setting credentials. Unified AWS Credentials describes this in detail.
DynamoDB Catalog
DynamoDB Catalog stores information in a DynamoDB table, configured with the `table_name` catalog property.
Read more from the DynamoDB Catalog documentation.
InMemory Catalog
The InMemory Catalog is a “special” implementation of the SQL Catalog. It leverages SQLite’s In-Memory Database to store the metadata pointer.
This is one of my favorite implementations of the Iceberg Catalog. It is ideal for use cases where an ephemeral catalog is needed. The metadata files are still stored in the filesystem.
For example:
from pyiceberg.catalog.sql import SqlCatalog
warehouse_path = "/tmp/warehouse"
catalog = SqlCatalog(
"default",
**{
"uri": "sqlite:///:memory:",
"warehouse": f"file://{warehouse_path}",
},
)There’s another implementation of the InMemory Catalog, which stores information as Python objects. It is mainly used for testing purposes. See InMemoryCatalog.
Custom Catalog
There’s a pluggable interface to use custom catalog implementations, which can be helpful in Bring-Your-Own-Catalog use cases. It’s provided as a feature in the `load_catalog` function
Read more from the Custom Catalog Implementations documentation.
For example:
from pyiceberg.catalog import load_catalog
warehouse_path = "/tmp/warehouse"
catalog = load_catalog(
"default",
**{
"py-catalog-impl": "pyiceberg.catalog.sql.SqlCatalog",
"uri": "sqlite:///:memory:",
"warehouse": f"file://{warehouse_path}",
},
)It is up to the catalog implementation to adhere to the behaviors of the catalog specification.
REST Catalog
The REST Catalog is a catalog based on the HTTP/RESTful protocol. It adheres to the client-server architecture. The REST Catalog client translates the catalog operation into HTTP requests and sends them to the REST Catalog server.
The REST Catalog server is a “wrapper” for the underlying catalog. The server listens to HTTP endpoints and translates the requests into specific catalog operations to be processed by the underlying catalog. For example, the REST Catalog server can be implemented with an underlying SQL Catalog.
The REST Catalog decouples catalog behaviors from implementation details and provides a more flexible interface for integration.
The REST Catalog API follows the Iceberg REST Open API specification.
Read more from the REST Catalog documentation and the Decoupling Using the REST Catalog page.
Spin up a REST Catalog instance
The PyIceberg repo spins up a REST Catalog server instance using docker for integration tests. The REST Catalog container is defined in `dev/docker-compose-integration.yml`.
Run the following command in the PyIceberg repo to start all services defined in the YAML file, including the `rest` service,
docker compose -f dev/docker-compose-integration.yml up -dThis will spin up a docker container for the REST Catalog server and expose port 8181.
Connect to the REST Catalog
For example:
from pyiceberg.catalog.rest import RestCatalog
warehouse_path = "/tmp/warehouse"
catalog = RestCatalog(
"default",
**{
"uri": "http://127.0.0.1:8181/",
"warehouse": f"file://{warehouse_path}",
},
)The REST Catalog server is reachable via localhost port 8181.
There are many configurations for the REST Catalog connection such as authn, authz, request signing, etc.
There are also many reference implementations for the REST Catalog server, including the Python REST Catalog, Polaris Catalog, and lots more.
Fin
This post shows a few ways to connect to an Iceberg Catalog. Once the connection is established, users can interact with the catalog in many different ways. For example, the Getting Started with PyIceberg page shows reading and writing an Iceberg table through the catalog. Another example is to use PyIceberg as a CLI tool, to quickly and easily inspect the catalog and its tables.
PyIceberg 0.7.0 was recently released, with a ton of cool features by many contributors. Please check out the library and the associated GitHub repo (apache/iceberg-python).
…
As always, I would love to chat about Apache Iceberg, Open Table Formats, and catalogs. The next few months will be very exciting in this space.